introduction
Recently I became aware of the canarytokens project by the guys over at Thinkst. The basic idea is to manipulate things like documents / services in such a way that usage thereof will trigger an alert via some form of ‘phone home’ feature. The is most probably better known as ‘honeydocs’. In the case of canarytokens, the phone home features can be either via a DNS or HTTP request coupled with a unique token. As paraphrased from the projects website, this is no new groundbreaking idea but just another usable one.
In this post, I just want to take a few moments and jot down my findings when investigating the documents generated by this project.
read the source luke
Most of the functionality that the canarytokens project provides for services make perfect sense. Things like the Web Bugs, DNS Tokens and SQL Triggers are not hard concepts to grasp. In fact, they mostly use the actual protocols used for the triggers. The odd one out in that list I guess is the SQL Triggers. From the code snippet for the trigger that is provided, one can see that it leverages xp_fileexist and xp_dirtree. Searching MSDN for this xp_fileexist function quickly reveals that its actually considered an “undocumented feature” (though I did not really bother trying to confirm this statement) that checks for the existence of a file. Besides the point, all this trigger does is compile a UNC path and executes the file existence check. This results in the DNS lookup happening to the canarytoken provided host once the SQL trigger files and tries to check if the file exists.
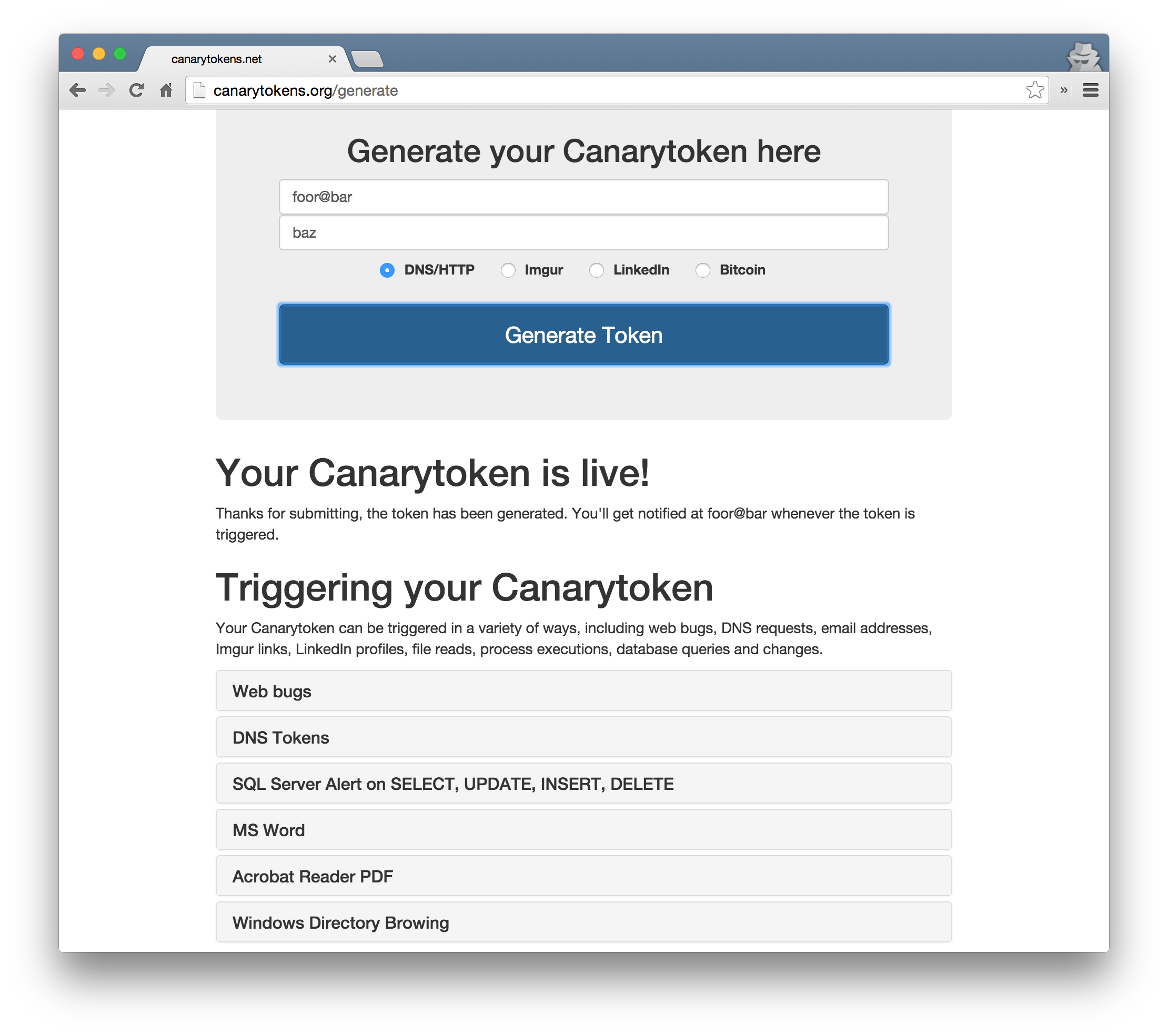
The more trickier ones in my opinion are the PDF and Microsoft Word honeydocs. Both of them use the DNS / HTTP thing, but I think the more interesting part is where exactly are these ‘tokens’ placed, and how are they executed?
I spent quite a bit of time getting my head around the published source code to learn the tricks. I was able to get a good idea of how it works, but realized it may be worth more if I inspected the generated docs themselves.
canarytokens generated PDF
My first target was the generated PDF. I used the website to generate myself a token and downloaded the PDF. I decided to fire up peepdf to analyze the internals.
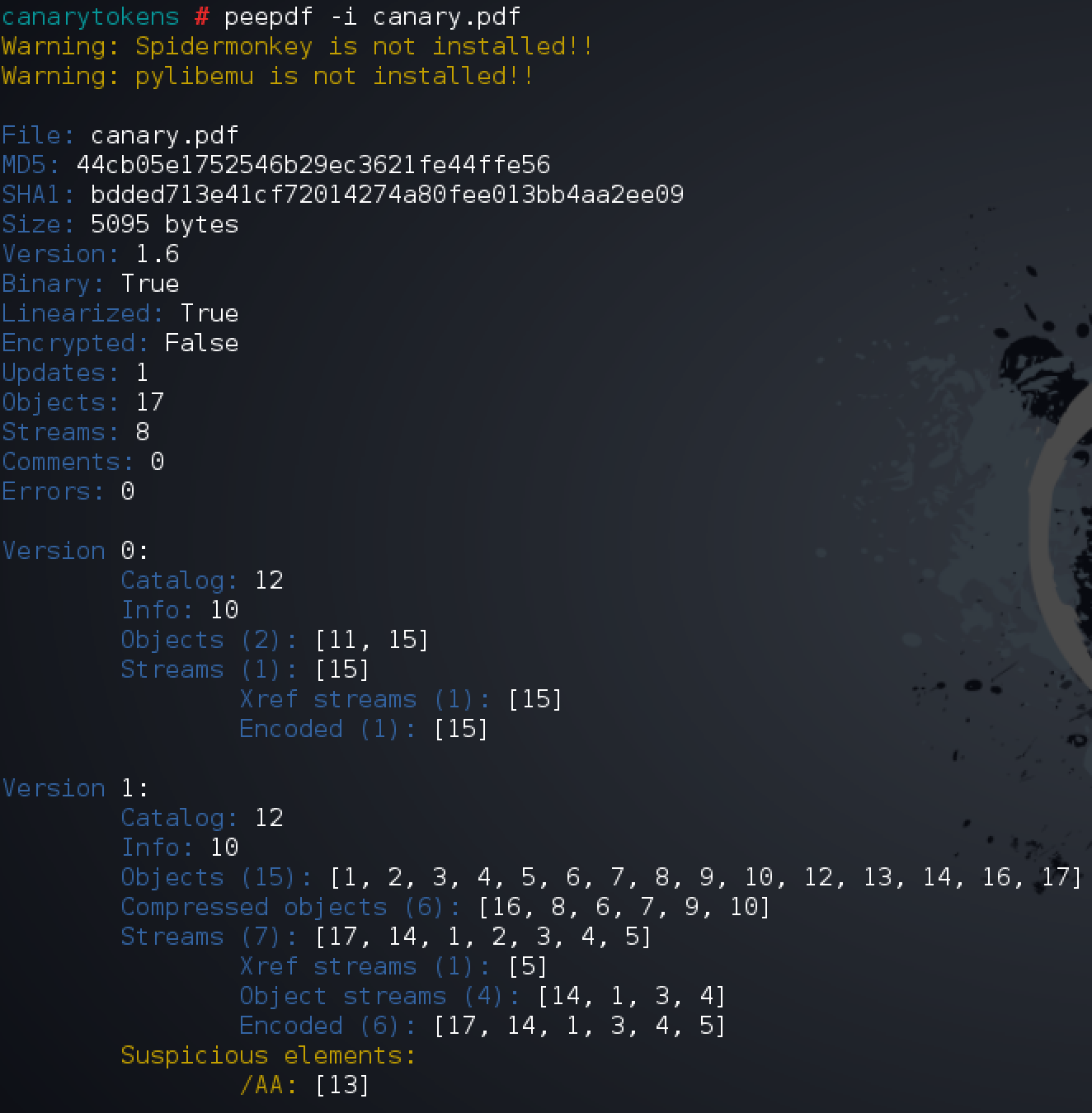
As can be seen in the above screenshot, the PDF version is 1.6. PeePDF has detected a suspicious element /AA so that will definitely be the first object we want to investigate. Admittedly I had to brush up a little on my PDF internals knowledge, and actually had to resort to the V1.6 PDF Specification to see what the /AA (and many other elements) denote.

An additional-actions field defining actions to be taken in response to various trigger events. Interesting. Lets take a closer look at the object.
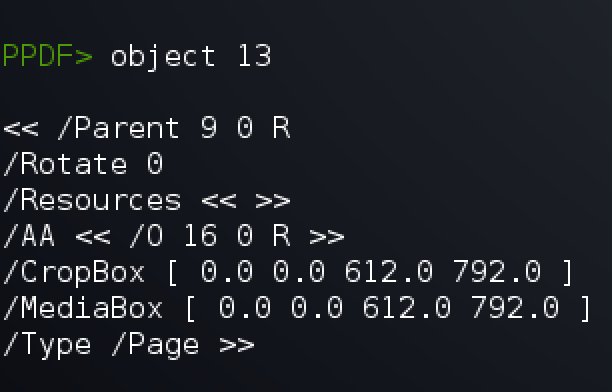
Here we can see a line /AA << /O 16 0 R >> which I assumed is referring to object 16. Lets see what that has for us.
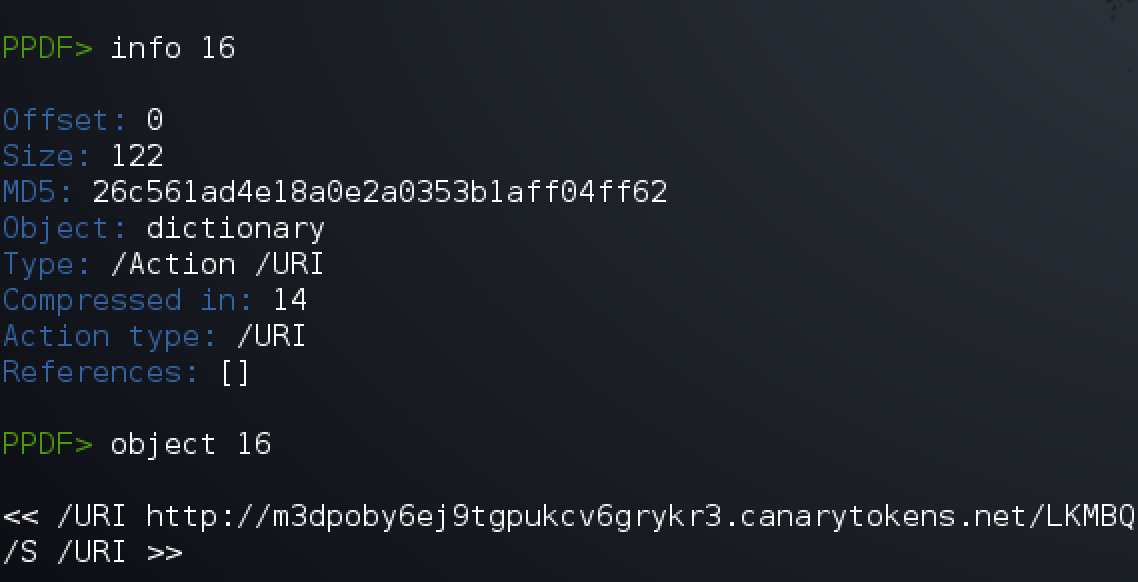
Well, there we have the canary trigger URL! Note that PeePDF automatically tries to decode objects if it can, so the raw object may have been encoded someway, but that does not matter :)
That is all good and well, but it did not really tell me how this is actually executed. So I tried to dig a little deeper and came up with a theory.
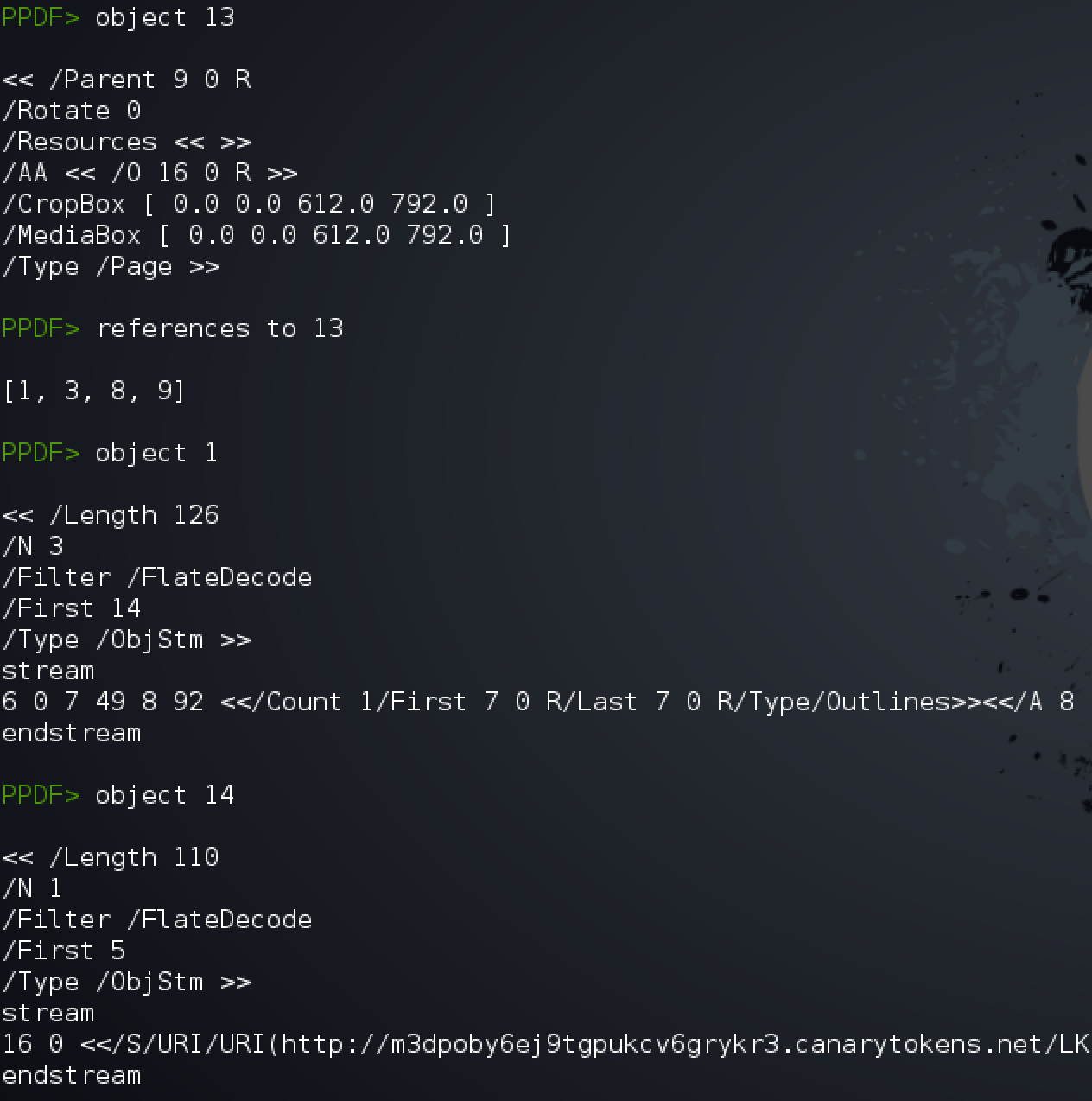
From the above screenshot, I theorized that when the PDF is opened and parsed it will start with Object 1. Object 1 has a /First 14 element which should be the byte offset to the first compressed object. Object 14 is a an Object Stream with another instance of the canarytoken URL as a URI object. From the specification doc, we can read that A URI action causes a URI to be resolved

So, my guess is as soon as the doc is opened, this URI will be resolved as part of the parsing process, and the canarytoken trigger fired. That left me satisfied in accepting how it works :P
canarytokens generated DOCX
The word doc on the other hand is a lot easier to understand. Downloading the generated honeydoc from canarytokens.org revealed to be a standard docx file.

This can be extracted and the inner workings of the document can be inspected. I have played with this type of phone home in a word doc, so, I was kinda expecting where this was going. I took the really easy route and just grepped the files from the docx archive for the word canary.
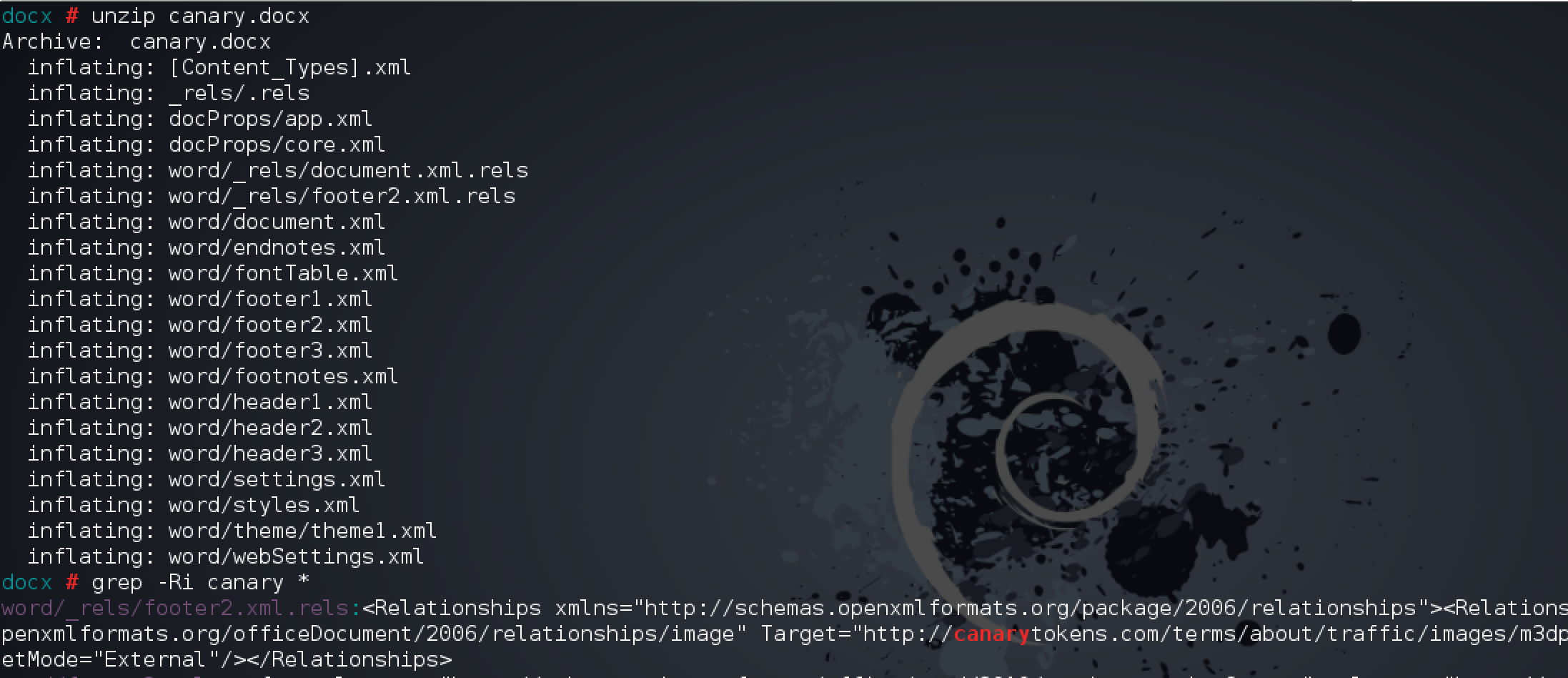
When you take a moment a read the Wikipedia entry for the Office Open XML Format, one will quickly see that it is possible to reference external images. It is for this reason that it is possible to have the word processor hit the trigger URL during parsing as it gets ready to pull the external image in.
conclusion
I think there is a lot of merit in this project. The methods used are obviously not fool proof, and if you are a really careful advesary and aware of these things then you will most probably not open docs from internet connected machines or ones without proper egress firewalling.
In my case, Little Snitch alerted me of the attempts to make the outgoing connections, so obviously that is a big give away for an attacker that was not previously aware of what was going on.